交通标志分类
Load The Data
Data is already prepared.
import pickle
training_file = 'data/train.p'
validation_file= 'data/valid.p'
testing_file = 'data/test.p'
with open(training_file, mode='rb') as f:
train = pickle.load(f)
with open(validation_file, mode='rb') as f:
valid = pickle.load(f)
with open(testing_file, mode='rb') as f:
test = pickle.load(f)
X_train, y_train = train['features'], train['labels']
X_valid, y_valid = valid['features'], valid['labels']
X_test, y_test = test['features'], test['labels']
Dataset Summary & Exploration
Show random pictures.
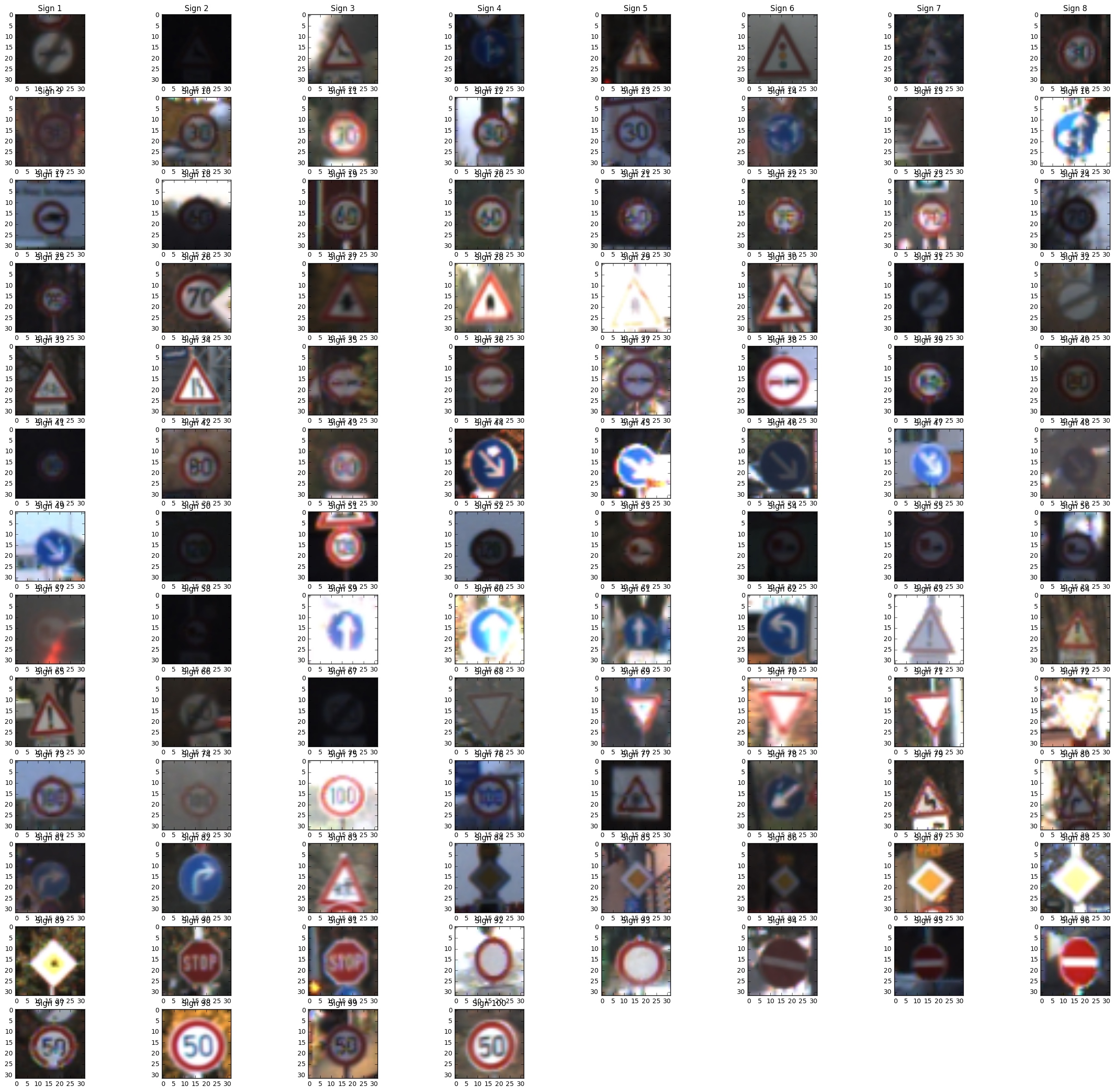
Show 64 sign in one category.

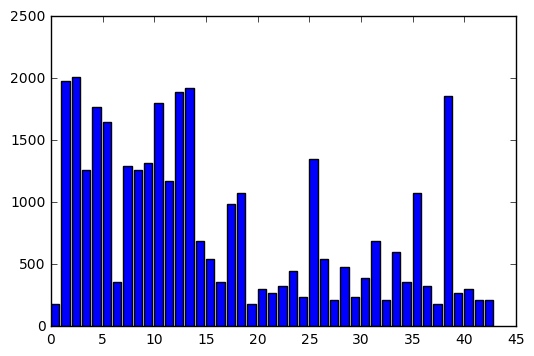
Data distribution.
Pre-process the Data Set
I used normalization here to make every pixel value in the range from -1 to 1, which makes the neural network can easily converge and avoid some numeric problems.
X_train = X_train / 128-1
X_test = X_test / 128-1
X_valid = X_valid / 128-1
Model Architecture
| Layer | Description |
|---|---|
| Input | 32x32x3 RGB image |
| Convolution 5x5 | 1x1 stride, valid padding, outputs 6 channel |
| Relu | |
| Max pooling | 2x2 stride, 2x2 size |
| Convolution 5x5 | 1x1 stride, valid padding, output 16 channel |
| Relu | |
| Max pooling | 2x2 stride, 2x2 size |
| Dropout | keep_prob=0.5 |
| fc | 400x200 |
| fc2 | 120x84 |
| fc3 | 84x43, output 43 class |
I have used a very simple Lenet network which has 2 conv layers and 3 fc layers.
Also, I add a dropout layer in front of the first fc layer.
The optimizer is adam, which can dynamically adjust the learning rate.
def LeNet(x):
mu = 0
sigma = 0.1
conv1_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 3, 6), mean = mu, stddev = sigma))
conv1_b = tf.Variable(tf.zeros(6))
conv1 = tf.nn.conv2d(x, conv1_W, strides=[1, 1, 1, 1], padding='VALID') + conv1_b
conv1 = tf.nn.relu(conv1)
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
conv2_W = tf.Variable(tf.truncated_normal(shape=(5, 5, 6, 16), mean = mu, stddev = sigma))
conv2_b = tf.Variable(tf.zeros(16))
conv2 = tf.nn.conv2d(conv1, conv2_W, strides=[1, 1, 1, 1], padding='VALID') + conv2_b
conv2 = tf.nn.relu(conv2)
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
fc0 = flatten(conv2)
x = tf.nn.dropout(x, keep_prob=0.5)
fc1_W = tf.Variable(tf.truncated_normal(shape=(400, 120), mean = mu, stddev = sigma))
fc1_b = tf.Variable(tf.zeros(120))
fc1 = tf.matmul(fc0, fc1_W) + fc1_b
fc1 = tf.nn.relu(fc1)
fc2_W = tf.Variable(tf.truncated_normal(shape=(120, 84), mean = mu, stddev = sigma))
fc2_b = tf.Variable(tf.zeros(84))
fc2 = tf.matmul(fc1, fc2_W) + fc2_b
fc2 = tf.nn.relu(fc2)
fc3_W = tf.Variable(tf.truncated_normal(shape=(84, 43), mean = mu, stddev = sigma))
fc3_b = tf.Variable(tf.zeros(43))
logits = tf.matmul(fc2, fc3_W) + fc3_b
return logits
Train and Validate the Model
To train the model, I used 50 epochs and batch_size of 64.
Learning rate is 0.001.
Optimizer is adam.
I tried several times to adjust this parameters, and found 0.001 is a proper learning rate. Also, epoch 50 is tested for avoiding over-fitting and under-fitting. Batch_SIZE 64 is the maximum number for my 8GB GPU memory.
import tensorflow as tf
from sklearn.utils import shuffle
EPOCHS = 50
BATCH_SIZE = 64
x = tf.placeholder(tf.float32, (None, 32, 32, 3))
y = tf.placeholder(tf.int32, (None))
one_hot_y = tf.one_hot(y, 43)
rate = 0.001
logits = LeNet(x)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=one_hot_y, logits=logits)
loss_operation = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer(learning_rate = rate)
training_operation = optimizer.minimize(loss_operation)
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(one_hot_y, 1))
accuracy_operation = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
saver = tf.train.Saver()
def evaluate(X_data, y_data):
num_examples = len(X_data)
total_accuracy = 0
sess = tf.get_default_session()
for offset in range(0, num_examples, BATCH_SIZE):
batch_x, batch_y = X_data[offset:offset+BATCH_SIZE], y_data[offset:offset+BATCH_SIZE]
accuracy = sess.run(accuracy_operation, feed_dict={x: batch_x, y: batch_y})
total_accuracy += (accuracy * len(batch_x))
return total_accuracy / num_examples
def show_prob(X_data):
sess = tf.get_default_session()
prob_ident = sess.run(tf.nn.softmax(logits),feed_dict={x: X_data})
top5 = tf.nn.top_k(prob_ident, k=5)
return sess.run(top5)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
num_examples = len(X_train)
print("Training...")
print()
for i in range(EPOCHS):
X_train, y_train = shuffle(X_train, y_train)
for offset in range(0, num_examples, BATCH_SIZE):
end = offset + BATCH_SIZE
batch_x, batch_y = X_train[offset:end], y_train[offset:end]
sess.run(training_operation, feed_dict={x: batch_x, y: batch_y})
validation_accuracy = evaluate(X_valid, y_valid)
print("EPOCH {} ...".format(i+1))
print("Validation Accuracy = {:.3f}".format(validation_accuracy))
print()
saver.save(sess, './lenet')
print("Model saved")
Then I get 94.2% acc.
Test the model
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('.'))
test_accuracy = evaluate(X_test, y_test)
print("Test Accuracy = {:.3f}".format(test_accuracy))
Get 0.931 Test Accuracy.
Test a Model on New Images
This test pictures are found on web and standard pictures, so it will be easy to recognize.
But the new images may (1)have different contrast, (2)never seen in the training set, and (3)effected by background.
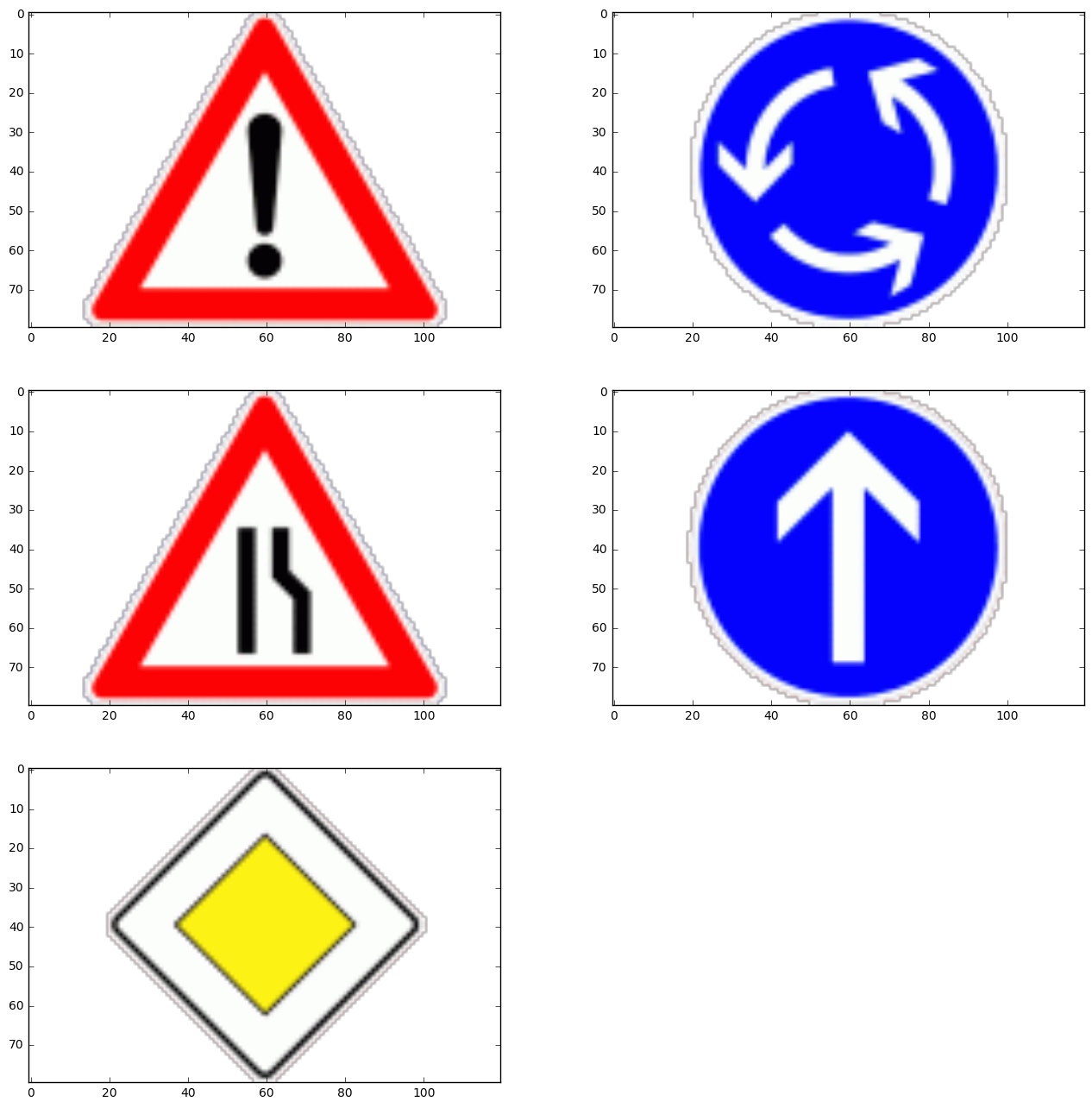
Preprocess them.
from scipy import misc
import numpy as np
def process_pic(path):
img = mpimg.imread(path)
img = img[:, 20:100, 0:3]
img = misc.imresize(img, (32,32,3))
img = img / 128 -1
# print(img.shape)
img = img.reshape(1,32,32,3)
print(img)
return np.array(img,dtype=np.float32)
Test accuracy
New pictures accuracy is larger than test accuracy because I only get 5 images and all the images is standard sign.
my_labels = [18 ,40,24,35,12]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver.restore(sess, tf.train.latest_checkpoint('.'))
my_accuracy = evaluate(imgs, my_labels)
print("Test Set Accuracy = {:.3f}".format(my_accuracy))
INFO:tensorflow:Restoring parameters from ./lenet
Test Set Accuracy = 100%
Output Top 5 Softmax Probabilities
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver.restore(sess, tf.train.latest_checkpoint('.'))
for i in range(5):
top_5 = show_prob(imgs[i].reshape(-1,32,32,3))
print(top_5)
INFO:tensorflow:Restoring parameters from ./lenet
TopKV2(values=array([[ 0.05911878, 0.04235243, 0.03344287, 0.03167986, 0.0302091 ]], dtype=float32), indices=array([[40, 12, 41, 11, 0]], dtype=int32))
TopKV2(values=array([[ 0.0536733 , 0.05091601, 0.04784877, 0.03567901, 0.03408691]], dtype=float32), indices=array([[12, 40, 3, 41, 0]], dtype=int32))
TopKV2(values=array([[ 0.05149816, 0.03681682, 0.03258161, 0.03189658, 0.03167427]], dtype=float32), indices=array([[40, 12, 41, 10, 11]], dtype=int32))
TopKV2(values=array([[ 0.0519179 , 0.04903445, 0.04526334, 0.036646 , 0.03531312]], dtype=float32), indices=array([[40, 12, 3, 41, 18]], dtype=int32))
TopKV2(values=array([[ 0.03191166, 0.03073219, 0.0281542 , 0.02638618, 0.02638551]], dtype=float32), indices=array([[40, 12, 11, 18, 25]], dtype=int32))